FABLE
A research project to fix broken links on the web
Broken web links
Problem
When users visit a page created many years ago, they are likely to find that some of the links on the page do not work. This robs them of relevant context that the page’s author meant to provide.
Similarly, users bookmark pages which are important to them, but often find that these bookmarks no longer work some time later.
In both cases, broken links are not merely annoyances that users have to put up with. Rather, these problems adversely impact the long-term availability of information and services on the web.
Prevalence
One important source of links that users care about are references and other external links included in Wikipedia’s articles. Even back in 2018, more than 9 million of the external links on Wikipedia no longer worked, affecting users’ ability to dig deeper and verify the articles which include these references.
Internet Archive’s approach
Today, when it finds a broken external link on any Wikipedia article, the Internet Archive augments that article with a link to an archived copy of the referenced URL; specifically, that copy whose time of capture is closest to when this URL was linked from the article.
Below is an example of how this works. On the Wikipedia page for Mars Express, external links from reference 3, 7, and 8 no longer work. References 7 and 8 have been augmented with a link to the Internet Archive’s copy of the URL. Whereas, reference 3’s link was never archived by the Internet Archive, and so, has been marked permanently dead.

Problems with archived copies
When a link does not work, it is not always the case that the page at that link no longer exists. Instead, a broken link is often merely because of a reorganization of the site hosting that page. The page has been moved to a new URL, and the site does not redirect requests for the page’s old URL to its new URL.
In such cases where a page still exists on the web, relying on an archived copy of the page has several shortcomings.
- First, the content and links on even the latest archived copy may be outdated. In the first example below, many articles on Wikipedia point to http://www.sister-cities.org/sci/aboutsci/mission, but the page at this link has now moved to https://sistercities.org/about-us/our-mission/. By visiting the live page on the web, users can engage with the organization (e.g., donate to it), which they cannot when visiting the archived copy of the broken link.
- Second, some pages enable users to interact with content retrieved from back-end servers. The second example below shows the page at https://trek.nasa.gov/mars/, where users can view imagery and perform analysis on data from Mars. Such functionality does not work on archived copies of the page’s old URL (http://marstrek.jpl.nasa.gov/), which is linked from Wikipedia.
- Last but not the least, the Internet Archive is far from complete. For a sizable number of broken links on Wikipedia, the Internet Archive lacks any archived snapshots, e.g., reference 3 shown above in the article about Mars Express.
Archived Copy
Stale Content

Screenshot of archived copy of http://www.sister-cities.org/sci/aboutsci/mission, a link which no longer works
Content on the page’s archived copy is stale and included links are out of date.
Inaccessible Service

Screenshot of archived copy of http://marstrek.jpl.nasa.gov/, a link which no longer works
On the archived copy, loading the current view spins forever and will never complete.
Live Web Page
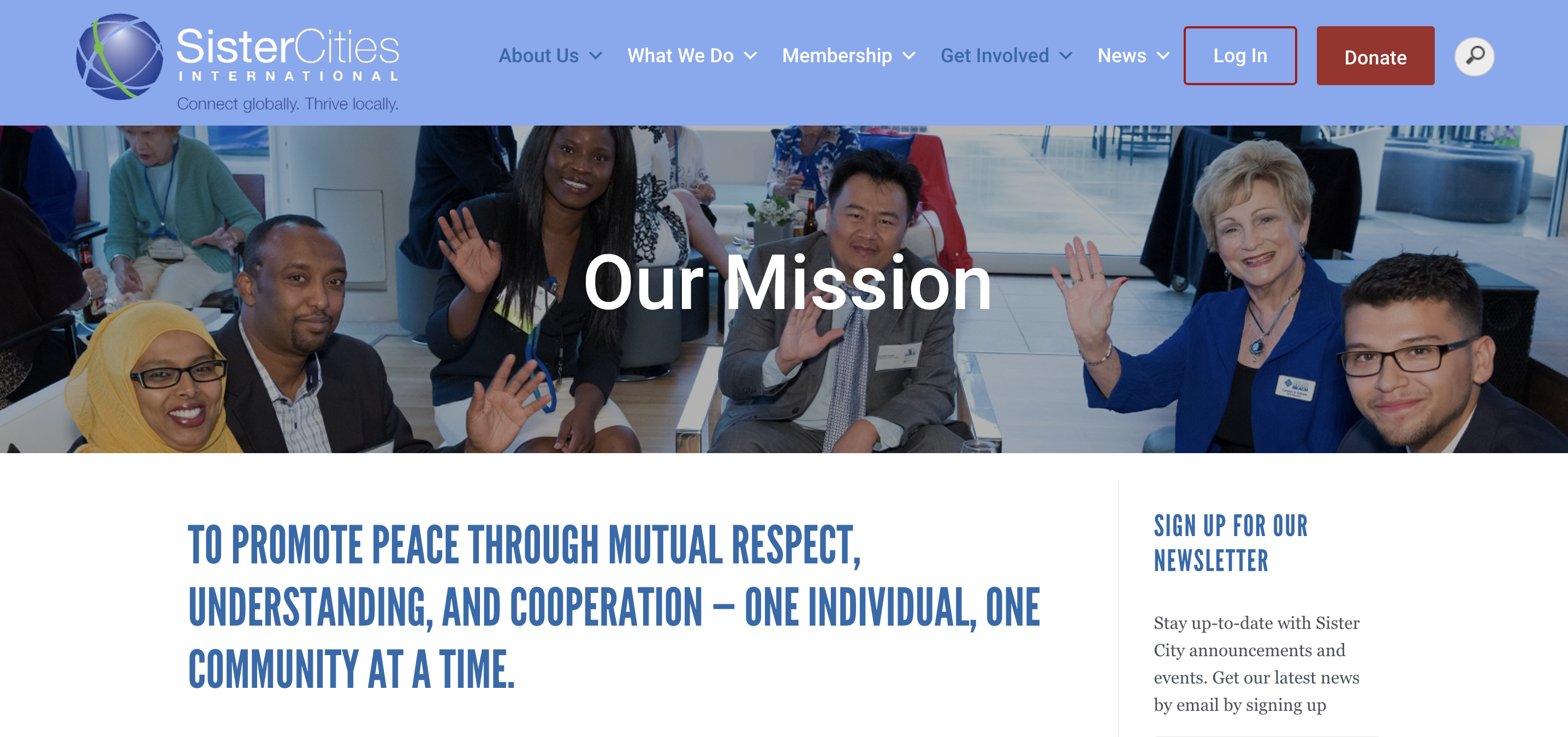
Screenshot of https://sistercities.org/about-us/our-mission/, new location at which page on the left now exists
The page on the web is visually appealing with active links to get involved and donate.

Screenshot of https://trek.nasa.gov/mars/, new location at which page on the left now exists
At the live page on the web, the feed is live and interactive, providing the best user experience.
Our solution: Find aliases for broken links
Given a URL which no longer works, if the page at that URL still exists on the web, we seek to find the page’s new URL. We refer to this new URL as the “alias” of the original broken URL.
We are building FABLE (Finding Aliases for Broken Links Efficiently), a system which leverages several sources of information to locate pages which previously existed at now dysfunctional URLs: archived pages on the Internet Archive, web search engines such as Google and Bing, and the live web.

FABLE relies on three techniques to find an alias for a broken URL: web search, historical redirections, and inference based on reorganization patterns.
Query search engines
First, FABLE follows the intuitive approach that users pursue when they encounter a broken link: query a web search engine using either the page title/content from an archived copy of the link or words/tokens from the linked URL. The search results will hopefully list the alias.
In contrast to a human user, who may visit the pages linked from the search results to check if any of those is the same page that was previously available at the link which is now broken, FABLE does not need to crawl any pages on the live web. Instead, FABLE collectively examines the search results for a set of similar broken URLs (e.g., URLs which are in the same directory on a site). For each URL in the set, FABLE identifies which of the search results, if any, is its alias by looking for a consistent transformation pattern from the old to new URLs. Compared to similarity in content between a live page and an archived page copy, this cross-verification across URLs serves as a more credible check of whether the alias identified for a particular URL indeed points to the same page. Moreover, not having to crawl any pages from the live web significantly improves FABLE’s efficiency and makes it more scalable.
Leverage historical redirections
Relying on web search to find the alias for a broken link does not always work: there may be no archived copy that can be used to construct search queries, content on the archived copy could be stale (e.g., for navigational pages, whose content changes often), the page may have little to no textual content (e.g., the second example above), and search engine indices are known to be incomplete.
Our second approach for finding aliases is based on the following observation: it is often the case that, for a URL that no longer works today, the site hosting it did previously redirect users to the corresponding alias. In other words, after reorganization, some sites initially redirect requests which specify the old URL for one of the site’s pages to the new URL for that page. But, these sites subsequently lose the state necessary to perform such redirections. For example, the URL http://www.kde.org/announcements/announce-1.92.htm does not work today, but previously redirected to http://www.kde.org/announcements/announce-1.92.php.
Therefore, given a broken URL, FABLE combs through the Internet Archive to see if a historical redirection from the URL to its alias exists. In doing so, FABLE takes care to identify and ignore soft-404s in which a URL was redirected to an unrelated page.
Infer patterns in URL changes
If all else fails, our last approach for finding a broken link’s alias is based on the following observation: when a site is reorganized, URLs for many pages on the site change, not just one. Using the aliases discovered using the first two approaches, FABLE attempts to learn the rules underlying the URL changes on every site. For this, FABLE leverages Microsoft Excel’s Flash Fill, a tool which uses a set of example inputs to predict the output for other inputs.

Current Status
We have implemented a preliminary prototype of FABLE, which runs on the Microsoft Azure cloud platform.
We have used our prototype to find aliases for 20,000 broken external links found on Wikipedia, Stack Overflow, and Medium. FABLE was able to find the new URLs for 23% of these links. Based on manual analysis of a randomly sampled subset, we estimate that 95% of these aliases are correct.
Acknowledgements
We thank the Alfred P. Sloan Foundation for their generous support of our work.
The Team



Aditya Chitta
M.S. Student

Bryan Chehanske
Undergraduate Student

Anish Nyayachavadi
M.S. Student