Jawa
Addressing the Adverse Impacts of JavaScript on Web Archives
The Need for Web Archives
The lifetime of the average page on the web is notoriously short. As a result, links to web pages often become dysfunctional over time. Simultaneously, the web is highly dynamic in nature, and the content on any web page is likely to change over time.
To combat these dual problems of link rot and content drift, a number of web archives exist, which periodically crawl and store web pages. Users can leverage these archives to refer to the content hosted on a specific URL, at any particular point in time from the past.
Context: JavaScript is a Key Component on Modern Web Pages
Modern web pages offer rich app-like functionality and are capable of adapting themselves to each user. This is partly made possible by the increasing amount of JavaScript that is executed when a user loads a web page in their browser.
Researchers have previously demonstrated the importance of executing JavaScript when web pages are crawled, so that all the resources embedded in the page are comprehensively captured. In turn, many browser-based web crawlers such as Brozzler and Browsertrix have been developed.
Negative Impact of JavaScript on Web Archives
In our work, we focus on two negative impacts of JavaScripts on web archives, which have not received much attention, to the best of our knowledge:
- Poor page fidelity: First, across multiple loads of a page, the manner in which JavaScript code on the page gets executed can vary based on a variety of factors such as 1) characteristics of the client device, e.g., Chrome or Safari, 3G or WiFi, or even the resolution of the display, and 2) values returned by the web browser in response to requests for random numbers, the current time, etc.
As a result, when a user loads an archived page snapshot, the browser’s execution of JavaScript on the page might cause it to request resources which were never crawled, resulting in missing content and browser runtime errors. Thus, the archived page ends up being a poor reflection of the original page on the web. - High operational cost: Fetching and executing JavaScript while crawling pages consumes a web archive’s network bandwidth and computational resources. Subsequently, storing crawled JavaScript files consumes storage.
However, a significant fraction of the JavaScript on a typical page relies on the user’s device interacting with the page’s servers, e.g., JavaScript that enables a page’s provider to push notifications to the user and JavaScript that enables users to post comments. Since such functionality cannot work on an archived page, crawling and storing the JS that powers these capabilities consumes network, compute, and storage, without any resultant benefits to preserving page fidelity.
Let’s look at each of these issues in more detail.
Illustrative Example
As an example of how JavaScript can impair the fidelity of archived pages, consider one of the Internet Archive’s snapshots for the page at oregonlive.com. Shown below is a portion of the screenshot captured by the Internet Archive when crawling this snapshot.
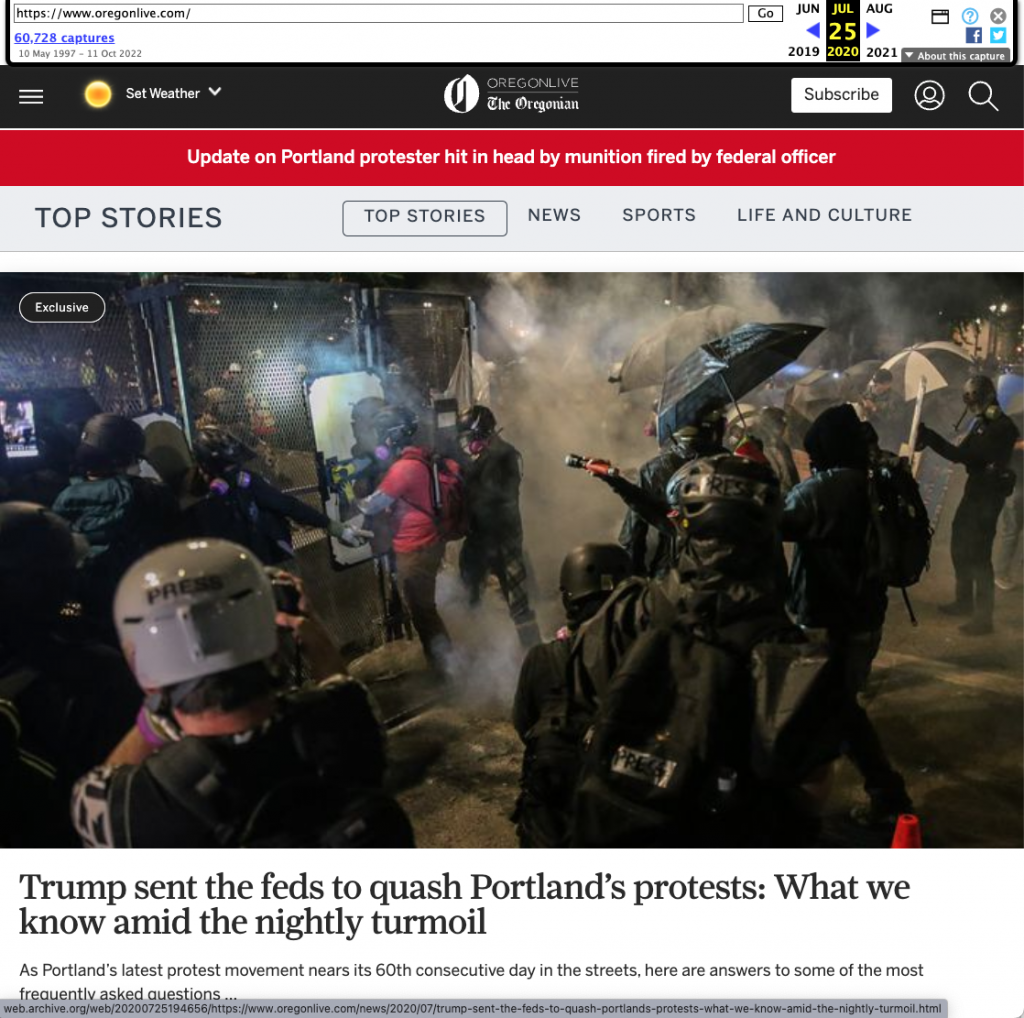
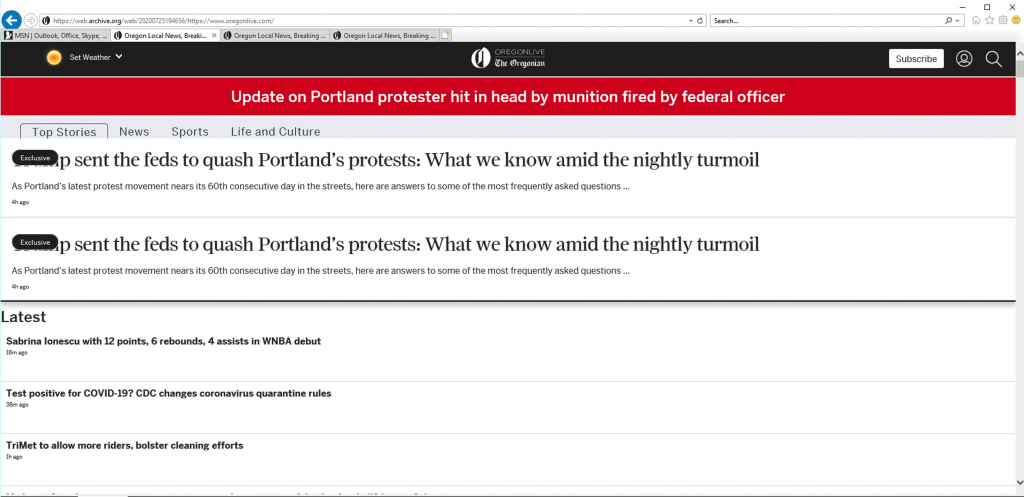
However, when we load this page snapshot using the Microsoft Edge browser, JavaScript on the page executes differently compared to when the Internet Archive crawled the page using a Chromium-based browser. As a result of the runtime errors and missing page resources, the page ends up looking as shown below.
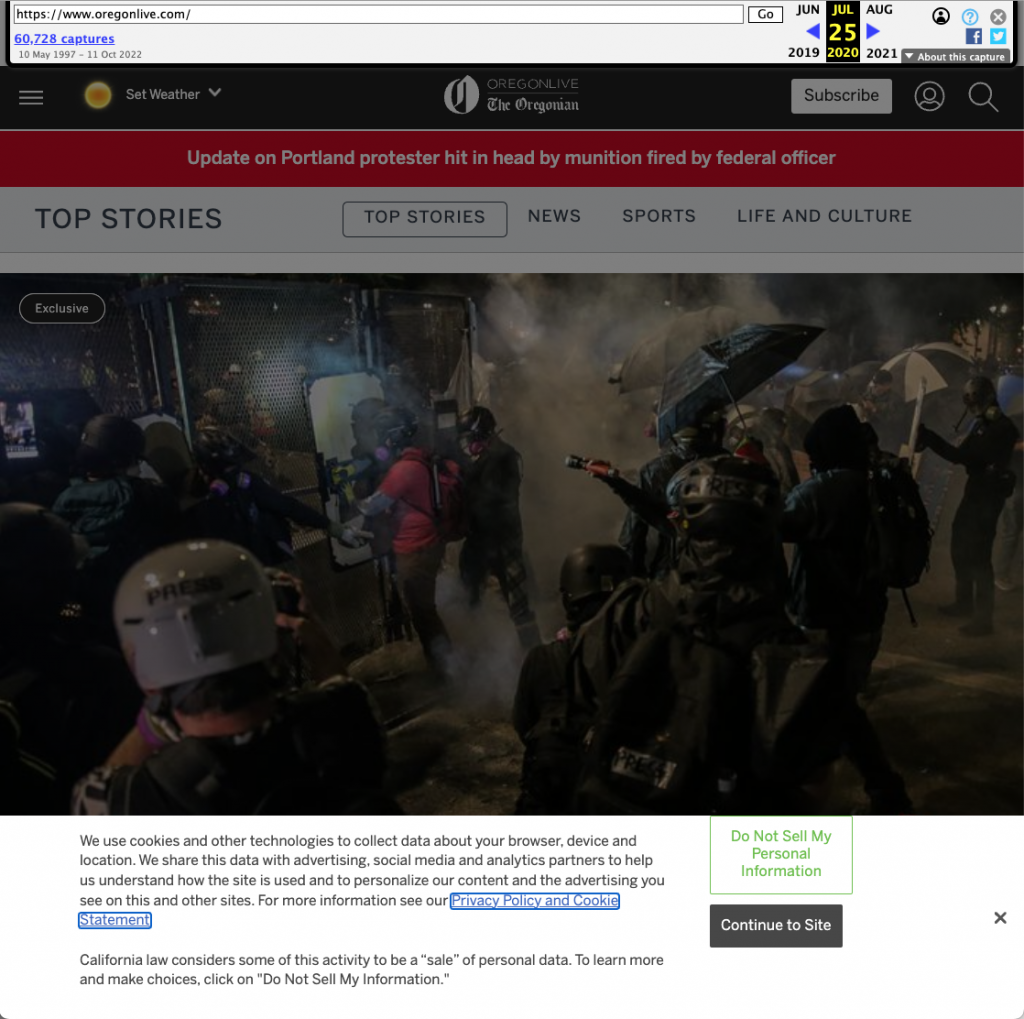
On the other hand, the total amount of JavaScript on this page snapshot is over 4.7 MB. While some of this JavaScript is often pruned out by users even on the live web (e.g., code responsible for advertisements and analytics), at least 800 KB of JavaScript on the page is important on the live web but serves no functional purpose on an archived page. For example, as shown below, when the load of this page snapshot completes, the JavaScript on the page displays a cookie consent banner at the bottom. Such functionality which requires communication with a page’s original servers will not function on archived pages.
Our Solution: JavaScript-Aware Web Archiving
To ensure that JavaScript has no impact on the fidelity of archived pages and to reduce the cost borne by web archives for fetching, executing, and storing JavaScripts, we have developed a new crawler that we call Jawa.
Eliminate sources of JavaScript variation
To eliminate the differences in resource URLs that are requested across different loads of the same page, Jawa eliminates the underlying sources of variation. To do so, Jawa tracks the values of each such source of variation when crawling a page, and enforces the same values when a user later loads the archived page snapshot.
Prune non-functional JavaScript code
Jawa identifies non-functional code using a filter list, akin to the lists used by browser extensions such as Adblock for blocking ads. When crawling a page, Jawa skips fetching any JavaScript file that matches its filter list. Doing so not only speeds up the crawling of pages (because of needing to fetch fewer resources and having to execute fewer scripts), but also reduces the amount of storage needed.
Preliminary results
From our research paper that describes Jawa, the key findings are as follows:
- To store a corpus of 1 million page snapshots that we downloaded from the Internet Archive, Jawa reduces the total amount of storage needed by 41%.
- On over 95% of pages in a corpus of 3000 pages, Jawa eliminates almost all failed network fetches when loading archived pages in a different browser than the one used to crawl these pages.
- Jawa improves the number of pages that can be crawled per hour by 39%.